

La Data ! La data ! La data ! Si un mot explose les compteurs d’occurrence dans les échanges entre les professionnels du marketing et des études, c’est bien celui-ci, le paradoxe étant que – comme bien souvent – ceux qui parlent le plus du sujet ne sont pas nécessairement ceux qui le maitrisent le mieux…
Face à l’injonction à s’approprier ces notions (sous peine de passer pour de vieux croutons) et à la complexité des discours (parfois volontairement entretenue) les non-initiés se retrouvent avec le douloureux sentiment de faire partie des « nuls » ! Et s’il était possible pourtant de rendre ces domaines un peu plus abordables pour le commun des mortels (en tout cas pour le petit monde des market researchers), en s’appuyant sur des experts plus à même de faire acte de pédagogie ?
C’est le pari que nous lançons ici, avec une première série de questions auxquelles répond Thierry Vallaud, un des spécialistes les plus reconnus du sujet, traducteur et adaptateur de l’ouvrage « Data mining – Découverte de connaissances dans les données» qui vient d’être ré-édité aux éditions Vuibert.
MRNews : Le mot « data » est très souvent marié à d’autres termes. On entend notamment beaucoup parler de « data sciences » ou de « datamining ». Ces notions sont-elles identiques ? Et si non, en quoi diffèrent-elles ?
Thierry Vallaud : Dans un article que j’ai écrit il y a déjà quelques années, j’évoquais l’idée que le terme de « data scientist » relevait purement du naming. Etre « statisticien » ou « data-miner », c’est perçu comme franchement ennuyeux… Etre data-scientist, c’est nettement plus sexy, c’est même un métier super hype ! (rires). Et, on le voit bien au travers de ces courbes, un terme a chassé l’autre.
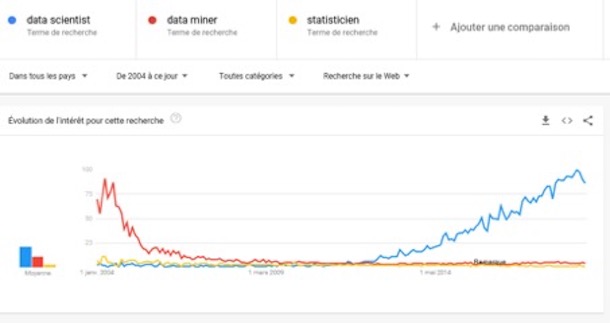
(source Google Trends)
Dans une présentation que j’avais faite en 2014 à l’EHESS, j’avais retracé l’invention du mot data science. Celui-ci a été proposé pour la première fois en 1998 par le professeur Wu de la Georgia Tech, au moment où il cherchait un nouveau nom à donner aux masters de statistiques désertés par les étudiants américains aux profits des MBA. Les disciplines universitaires aux US se rajoutant alors toutes le mot « science » : management science, information science, decision science… C’est lui-même qui m’a dit avoir hésité avec «statistics science». Pour justifier l’ajout de « science » il élargissait le scope des « statistiques » à l’interaction qu’elles se doivent d’avoir avec les autres matières pour apporter des enseignements réels : l’informatique, les mathématiques, mais aussi et surtout les sciences de gestion, la sociologie, l’ethnologie, la psychologie.
Les data sciences constituent donc bien un champ plus large que celui du datamining et des statistiques ?
Oui, tout à fait. La data irradiant les domaines que nous venons d’évoquer, les statistiques s’élargissent ou se spécialisent pour ces différentes «sciences ».
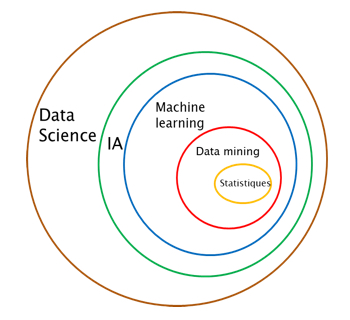 Les statistiques et le data mining peuvent ainsi être considérées comme des outils de la data science. Les algorithmes du data mining sont les mêmes que ceux du machine learning mais la puissance des ordinateurs permet de les maximiser, de les mener plus loin (c’est ce que l’on appelle le « deep learning ») et de manière plus automatique. La machine auto-apprend (c’est le principe de l’Intelligence Artificielle), mais ce sont les mêmes fondamentaux algorithmiques. La data science, c’est donc le champ scientifique globale de toutes ces disciplines.
Les statistiques et le data mining peuvent ainsi être considérées comme des outils de la data science. Les algorithmes du data mining sont les mêmes que ceux du machine learning mais la puissance des ordinateurs permet de les maximiser, de les mener plus loin (c’est ce que l’on appelle le « deep learning ») et de manière plus automatique. La machine auto-apprend (c’est le principe de l’Intelligence Artificielle), mais ce sont les mêmes fondamentaux algorithmiques. La data science, c’est donc le champ scientifique globale de toutes ces disciplines.
Et puis si vous voulez impressionner votre maman qui vous aime mais ne comprend toujours pas ce que vous faites, il n’y a pas d’hésitation à avoir, dites-lui que vous êtes un data scientist, un « vrai » !
L’informatique n’est-elle pas en train de prendre le pas sur les statistiques ?
Après le CRM, la Business Intelligence, l’Analytique, l’informatique est en effet en mal de sujets « chauds ». Elle trouve un nouveau « pouvoir » avec la Data Science et l’intelligence Artificielle, un nouveau cycle s’ouvrant à elle pour mobiliser des ressources et de l’énergie (acheter de très grosses machines et lancer des mégas projets). D’autant plus qu’une belle opacité est de mise, et que les « métiers » ne veulent souvent pas faire l’effort cognitif de comprendre les aspects technologiques. Le « big data » est arrivé au bon moment avec son déluge de données et d’architecture avec des noms d’animaux transgéniques, de recherche élastique, d’étincelles et de langages ésotériques pour redonner le « plein » pouvoir à l’informatique.
Il y a néanmoins un vrai changement de contexte au regard des données disponibles, qui peut expliquer ce gain de pouvoir de l’informatique…
Il est vrai que la croissance des données est exponentielle. Mais, d’une part, cela ne date pas d’hier, cette tendance est à l’oeuvre depuis plus de trente ans. D’autre part, il ne faut pas oublier qu’une partie importante des « nouvelles » données non structurées n’ont qu’un intérêt socialement limité : c’est le syndrome des photos de chatons échangés sur Facebook. C’est très mignon, mais on en fait quoi ? Et par ailleurs et enfin, compte tenu de l’évolution de la puissance des machines et de la décroissance des coûts, on dispose aujourd’hui de ressources de calcul jamais atteintes auparavant, disponible pour le plus grand nombre dans le cloud et quasiment en mode « plug and play ». Ne perdons également pas de vue que la plupart des entreprises n’ont pas le volume des données GAFA.
Il n’y a pas plus amusant que l’informaticien qui découvre les statistiques avec le mot « machine » devant « learning » et « artificielle » devant « intelligence ». Avec la croissance des données, voilà un nouvel eldorado pour l’IT. On y rajoute du « code » : R, Python, Scala… De belles barrières à l’entrée replacent ainsi l’IT au centre des décisions et des budgets. Le darwinisme du pouvoir est sauf ! Et le Chief Technical Officer n’est pas prêt de laisser le siège qu’il a conquis au sein des CODIR !
Dans beaucoup d’entreprises, les équipes études souffrent de cette prise de pouvoir de l’informatique…
C’est vrai. Mais elles ne doivent pas baisser les bras pour autant. La connaissance client n’est pas l’informatique. Cette dernière n’est jamais qu’un outil à la disposition des métiers, à fortiori dans le domaine des études. Et, précisément, le choix des outils ne doit surtout pas être laissé à l’IT, qui considère que ceux-ci sont substituables entre eux, et cache une relative non-maitrise par l’expression exacerbée des besoins des métiers. Or, le bon ouvrier sait quel est pour lui le « bon » outil sans déléguer cette mission à un tiers. Dans combien d’entreprises les utilisateurs se demandent pourquoi l’IT a fait tel choix plutôt que tel autre ? Je pense que l’on ne doit pas être loin des 100%.
L’injonction « tous codeurs ! » est très souvent reprise dans les médias. Faut-il la suivre ?
Surtout pas ! Et encore moins aujourd’hui qu’hier, avec l’arrivée ou le déploiement sur le marché de solutions packagées bien plus efficaces que le «code» sur le plan de la productivité. Ces solutions sont nombreuses : Modeler d’IBM, qui redevient Watson, Azure Machine Learning, Knime, Dataiku dans une moindre mesure, et également des outils en open sources. La plupart sont disponibles en ligne, pour quelques centaines d’euros par mois pour les plus «honnêtes». La diffusion de leur usage contribuera à atténuer la pénurie de data scientists, tout en permettant de travailler de façon très efficace et qualitative. Elles ouvrent la possibilité aux différents « métiers » concernés de reprendre la main via des interfaces objet (GUI) et de s’affranchir de l’informatique qui peut se concentrer sur ces tâches de mise à disposition des données propres et renseignées avec les bons niveaux de flux et de performance entre les phases de tests et de productions. Il faut néanmoins avoir quelques connaissances statistiques pour les exploiter, c’est évident.
Ces solutions permettent de faire du data mining sans toucher au code ?
Oui, c’est cela. Les meilleures d’entre elles se connectent directement à toutes les sources (crawl du Web, BDD internes, cloud…), gèrent de manière transparente les aspects « big data » en créant le code, permettent l’insertion si nécessaire de codes supplémentaires (Python/R/SQL, Scala…). Elles ouvrent également la possibilité de mettre en production immédiate des modèles, ou bien éventuellement d’exporter tous ceux qui ont été créés dans la syntaxe choisie. On en revient bien aux fondamentaux : le data mining, , les statistiques, l’analyse des données par les praticiens ou les hommes métiers qui leur sont dédiés. Encore faudrait -il s’en rendre compte. Cette vulgarisation simple est le but de la nouvelle édition de ce livre, avec des exemples sur Modeler/Watson d’IBM et sous forme d’une syntaxe packagée sous R.
Donc non, surtout pas « tous codeurs », mais codeur si je veux et quand je veux ! Je préfère nettement la proposition « Tous créatifs ! ». C’est plus drôle, et socialement bien plus efficace.
En somme, pour accéder à la Data Science, rien de tel qu’un data mining par la pratique ? D’où l’idée de cet ouvrage ?
C’est exactement cela ! La seule façon de passer du discours à la réalité, c’est le faire soi-même. Comme le disait ma grand-mère, il y a une belle différence entre les « faisous » et les « disous ». Les « disous » ne manquent pas, il faut encourager les bonnes volontés à devenir des « faisous ». C’est tout l’objet de ce livre, qui a été conçu pour permettre au lecteur de choisir ces outils packagés, d’élaborer lui-même des modèles, et de savoir parler précisément de ce qu’il fait sans se limiter à évoquer des concepts généraux. Nous l’avons intitulé « Découverte de connaissance dans les données : une introduction au data mining » pour rester dans le bon champ sémantique, celui du « savoir-faire ». Je crois que le processus « CRISP DM » (Cross Industry Standard Process for Data Mining ) est la bonne méthode à suivre pour commencer pas à pas. Au fil des chapitres du livre, le lecteur peut apprendre à passer peu à peu à la modélisation. D’abord sur des démarches relativement simples comme la régression logistique et les arbres de décision ; puis, en gagnant en expertise, sur des éléments plus complexes tels que les réseaux neurones ou les cartes auto organisatrices. Tout cela de la façon la plus transparente possible. Les grandes règles pour obtenir des modèles efficients sont rappelées à chaque chapitre : la bonne préparation des données, l’équilibrage de la variable à expliquer, la division des données en ensemble d’apprentissages, le test et/ou la validation… L’analyse des résultats se veut claire, sans jargon et orientée métier. Je précise pour qu’il n’y ait pas de malentendu que l’ouvrage a été originellement rédigé par Daniel T. Larose et Chantal D. Larose, j’en suis simplement le traducteur et l’adaptateur.
Voyez-vous quelques derniers conseils à ajouter en conclusion ?
Oui, j’en vois trois. Choisis un outil avec une interface et ne code que quand tu veux (ou quand tu ne peux pas faire autrement). Eduque ton CTO, parce que finalement, il est plutôt gentil. Et surtout : fais du rock and roll !! (rires)
POUR ACTION
• Echanger avec l’interviewé(e) : @ Thierry Vallaud


