

Depuis que les études marketing existent et plus largement depuis que l’on s’intéresse scientifiquement à la parole des individus, tirer du sens de leurs libres propos a toujours constitué un réel enjeu. Mais cet enjeu est précisément en train de s’amplifier considérablement avec le développement des réseaux sociaux et l’exploitation à des fins d’études des discussions sur le web.. Qu’en est-il donc des outils et des logiciels permettant d’analyser cette parole ? Quoi de neuf en la matière ? Quels sont les progrès récents enregistrés dans ce domaine ? Pour quels usages ? Ce sont les questions que nous avons posées à Jean Mascarola, fondateur de Sphinx Développement, à l’occasion du lancement annoncé de leur nouvelle solution logicielle, Sphinx Quali.
On parle aujourd’hui beaucoup du Big Data, qui est le thème de notre dossier du mois. Et dans ce contexte, on entend dire un peu tout et son contraire sur les possibilités que cela ouvre pour la communauté des marketeurs et des gens d’études. Quelle est votre vision à ce sujet ?
Dans notre vision des choses, le développement du web et des réseaux sociaux représente une opportunité évidente et majeure pour les études marketing. Mais on voit aussi pas mal d’acteurs promettre un peu la lune. On capterait ce qui est disponible gratuitement sur le web, et on le transformerait en décisions, comme sous l’effet d’une baguette magique. Cela ne correspond pas à notre philosophie. Nous nous efforçons d’avoir une démarche réaliste, en proposant des outils et des services fiables qui facilitent le plus possible le travail des équipes marketing et des chargés d’études lorsqu’ils souhaitent exploiter les discours, en particulier ceux des consommateurs. C’est cette logique qui nous amené à développer Sphinx Quali, que nous allons très prochainement mettre sur le marché.
Quels sont les principaux besoins auxquels doit répondre cette solution ? J’imagine que l’écoute du web est une des composantes les plus essentielles…
En réalité, l’outil a été conçu pour répondre à trois grandes familles de problématiques. Vous avez raison, l’analyse de ce qui est dit sur les réseaux sociaux et les forums en fait partie. Plus largement, l’outil permet d’analyser ce que l’on appelle les contenus textuels non structurés. Cela comprend les textes rédigés sur les réseaux sociaux, mais aussi les articles de presse, les emails, les discours politiques, et par extension tout texte, quel qu’il soit. C’est une des problématiques qui, vous l’avez souligné, fait beaucoup parler d’elle. Mais le logiciel permet aussi de répondre à d’autres besoins, peut-être plus classiques, mais importants. Je pense en particulier au traitement des questions ouvertes dans le cadre des enquêtes (satisfaction, tests produits,…). Et aussi à la réalisation d’études qualitatives, avec des entretiens individuels ou des focus group.
Nous rentrerons plus dans le détail de ce qu’apporte votre solution Sphinx Quali pour ces différentes problématiques. Mais très globalement, quels sont les grands progrès que vous avez intégrés avec le développement de cet outil, et quels sont donc les bénéfices pour les utilisateurs ?
Il y a en fait trois grands axes de progrès avec Sphinx Quali. Le premier progrès réfère à la notion d’intégration. C’est à dire que nous avons regroupé dans une même solution des moyens qui étaient jusqu’ici accessibles par différents logiciels spécifiques. On retrouve les outils d’analyse de contenu dans leurs contours traditionnels, les approches de données textuelles, et l’ingénierie linguistique, qui est la grande nouveauté technologique. On mobilise ces trois ressources dans une même offre. L’avantage pour le client est qu’il dispose ainsi d’une combinaison qui lui coute nettement moins cher.
Le 2ème axe de progrès porte sur un aspect d’automatisation. Habituellement, l’utilisateur doit en passer par un nombre important de manipulations avant de parvenir à un résultat intéressant. Pour lui éviter cela, nous avons introduit ce que l’on appelle des synthèses automatiques. Si l’on s’intéresse à ce qui est dit sur le web sur un sujet comme celui de la vaccination par exemple, il suffit de se loguer sur le réseau, d’écrire « vaccination ». En 2 clics, vous disposez des caractéristiques linguistiques associées à ce sujet à ce thème sur le web et les réseaux sociaux.
Si j’entends bien, l’utilisateur gagne du temps en évitant de tâtonner sur la mise en œuvre mais aussi sur la définition des étapes d’analyse…
C’est tout à fait cela. Il dispose d’un mode opératoire efficace. Le dernier point de progrès a trait à l’intégration de services. En tant que client, on ne vous « abandonne » pas avec le logiciel. On vous donne la possibilité d’être aidé dans l’approfondissement de ce que produisent les automatismes. Ou bien encore nous faisons du développement complémentaire en fonction des besoins de l’entreprise, par exemple pour automatiser l’analyse des flux de messages qui lui parviennent.
Pour être le plus concret possible sur les possibilités du logiciel, peut-on évoquer les différents outputs qui sont générés, en particulier dans l’analyse des contenus textuels ? Vous avez utilisé le terme d’automatisme : qu’est-ce que l’utilisateur obtient en termes de livrables, et quels sont ceux qui sont fondamentalement nouveaux ?
En fait l’utilisateur obtient ce que nous appelons une synthèse, qui se décompose en plusieurs pages. La première d’entre elle présente les mots et les concepts clés qui sont contenus dans le texte analysé, ceux les plus fréquents. C’est ce qui procède d’un repérage des catégories grammaticales, dans un protocole où l’on retrouve la forme racine des mots. Cela repose sur l’exploitation d’un thesaurus, sachant que l’on peut effectuer des réglages : soit on reste relativement « macro » avec une trentaine de concepts. Ou bien l’on descend à un niveau plus fin avec 3600 concepts. Je précise que ce thesaurus est général ; il est donc parfois nécessaire de le compléter pour bien l’adapter au secteur d’activité dont il est question.
C’est la vision globale ?
Exactement. On obtient ensuite les catégorisations thématiques du corpus. C’est à dire que l’on présente les 3 à 5 grands types de discours, en s’appuyant sur un protocole de classification hiérarchique descendante. C’est un aspect extrêmement important dans l’analyse, sur lequel notre logiciel propose deux avantages essentiels : l’automatisation, mais aussi le fait que nous ayons intégré un moteur sémantique. Pour l’utilisateur, cela signifie que l’on peut mener la classification non pas sur des mots, mais sur des concepts. On dispose ainsi de classifications plus signifiantes, et plus robustes. Concrètement, comme le montre l’illustration, on obtient ainsi autant de nuages de mots qu’il y de grands types de discours, avec des termes qui s’affichent dans une police plus ou moins importante selon leur fréquence dans les discours. Chaque grand type de discours est caractérisé par les mots clés qui le distingue, et par les verbatim qui les illustrent. (figure 1 : exemple du Reblochon)
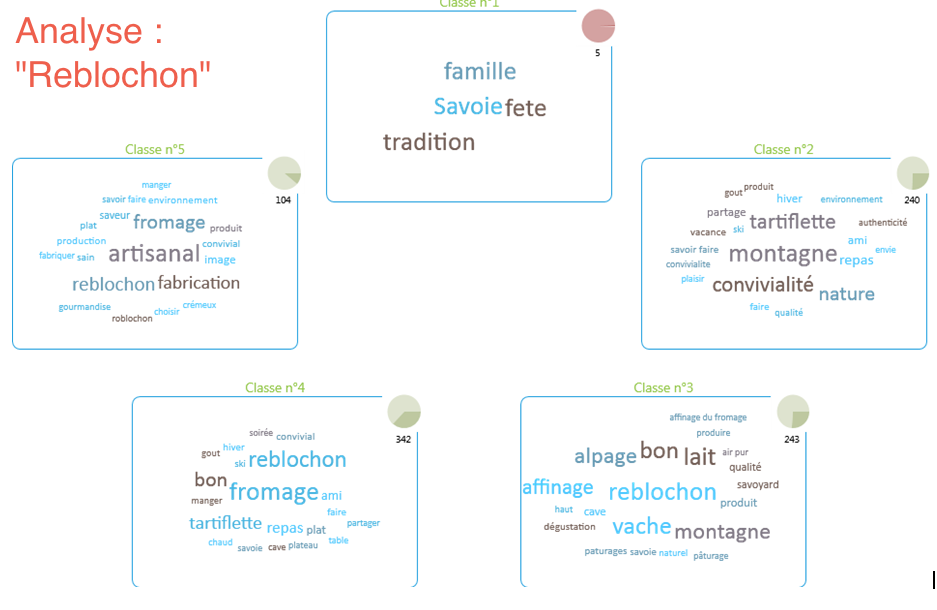
On a identifié des types de discours. Mais est-ce que cela renvoie aux différents types de personnes qui se sont exprimées ?
Pas nécessairement. Mais c’est très précisément ce que l’on obtient dans la suite de cette synthèse, qui a pour objet de caractériser ces catégories de discours. Qu’est-ce qui distingue celui qui s’exprime selon telle ou telle catégorie de discours ? On va donc utiliser les caractéristiques extérieures au texte disponibles, comme le sexe du locuteur, la date, la localisation géographique,… Et on ne va mettre en évidence que ce qui est influencé par ces éléments, que nous appelons des contextes. On est ainsi dans une logique de segmentation, on met le focus sur les différents types de discours.
Est-ce que d’autres éléments sont inclus dans cette synthèse ?
Oui, il y a un dernier éclairage extrêmement important, avec une vision graphique de l’orientation des opinions : quel est le pourcentage des opinions positives, négatives ou neutres ? L’utilisateur obtient également la vision à la fois des mots et des contextes spécifiquement associés à ces orientations. (cf. figure suivante)

Je reprends ce dernier point, qui est bien sûr très parlant pour ce qui est du sens des discours. Est-ce que cela constitue une nouveauté absolue ?
Ce qui est nouveau, c’est que l’on intègre les ressources de l’ingénierie linguistique. Dit autrement pour l’utilisateur, on avait bien cette notion d’orientation des discours dans les versions antérieures, mais selon une vision assez pauvre, qui supposait un travail important pour le chargé d’études. Il peut désormais l’obtenir automatiquement, et immédiatement.
Voyez-vous d’autres fonctionnalités importantes à évoquer ?
Oui. Je pense à un point qui a trait au travail d’analyse réalisé par les qualitativistes, ou bien encore dans le traitement des questions ouvertes. Dans ce type de travail, la première étape consiste à composer une grille de codification pertinente. En général, on définit cette grille sur la base d’un nombre conséquent de répondants, une centaine par exemple. Mais il y a toujours un risque, celui de passer à côté d’une certaine variété de discours. Notre outil apporte une aide précieuse en ce sens, d’une part parce qu’il aide le chargé d’études à établir une grille qui respecte réellement la diversité et la variété des discours. Et d’autre part parce qu’il va permettre de coder automatiquement les textes selon cette grille, via un processus d’apprentissage.
Quelles sont les limites que vous identifiez aujourd’hui dans les possibilités de ce logiciel, et quels sont les développements futurs que vous prévoyez de réaliser ?
Il y a une petite limite pour ce qui est de la langue. L’analyse de contenu, la classification, et toute la statistique textuelle fonctionnent à peu près sur toutes les langues. Par contre, l’analyse sémantique, qui repose sur le thesaurus, dépend des langues. Et actuellement, nous sommes limités au français sur ce point. Mais cette limite est toute relative puisqu’il est possible de travailler sur des textes après être passé par une traduction automatique, (comme avec ‘google traduction’ par exemple). On obtient du mauvais français, mais ce n’est pas un problème pour l’analyse de l’orientation des textes. Un projet de court terme est de faire en sorte que cette traduction automatique soit intégrée dans les fonctionnalités de Sphinx Quali. Un autre point est que le logiciel n’intègre pas le traitement des images. Cela fera partie des développements futurs.
En termes de niveau de prix, combien coûte ce type de logiciel ?
Nous sommes sur des niveaux de coût de licence annuel qui vont de 990 € à 1500 € par an, selon que les clients soient déjà utilisateurs de Sphinx iQ ou pas.
Faut-il nécessairement acquérir le logiciel pour obtenir ces analyses ?
Nous pouvons parfaitement effectuer la prestation via notre entité Sphinx Institute, soit dans le cadre d’un besoin ponctuel, ou bien dans un process systématique et automatisé. C’est ce qui nous permet de répondre aux besoins d’une population très large, qu’elle ait un profil études ou pas.
POUR ACTION
• Echanger avec l’interviewé(e) : @ Jean Moscarola


